
Apakah kalian tahu bahwa data yang disajikan di internet khususnya sebuah website bisa kita extract dengan menggunakan teknik scraping?
Ya, Web scraping adalah teknik mengambil data dari sebuah website secara otomatis menggunakan script atau program. Dengan web scraping, kita bisa mengumpulkan artikel, judul, tanggal publikasi, hingga isi konten dari berbagai situs. Studi kasus pada artikel ini, kita menggunakan website berita seperti Kompas.com untuk ekstraksi data artikel seperti judul, link dari artikel, serta gambar dari artikel tersebut. Tapi perlu diingat, tutorial pada artikel ini hanya untuk edukasi semata dan tidak diperuntukkan untuk penyalahgunaan data ataupun melanggar ketentuan yang berlaku di website terkait.
Apa Manfaat Dari Web Scraping?
Scraping sebuah website memiliki banyak manfaat, terutama bagi developer, peneliti data, dan digital marketer. Dengan web scraping, kita bisa mengumpulkan data secara otomatis tanpa harus menyalin satu per satu secara manual. Beberapa manfaat utama dari web scraping antara lain:
- Mengumpulkan Data Berita Secara Cepat
Dengan web scraping, data berita dari situs populer seperti Kompas.com dapat dikumpulkan untuk dianalisis, misalnya tren teknologi terbaru atau isu yang sedang hangat.
- Analisis Tren Pasar dan Kompetitor
Banyak perusahaan menggunakan web scraping untuk memantau harga produk, strategi kompetitor, serta tren pasar yang sedang berkembang.
- Membangun Dataset untuk Machine Learning
Web scraping bisa dimanfaatkan untuk membuat dataset, misalnya teks artikel berita, yang kemudian digunakan dalam proyek Natural Language Processing (NLP) atau sentiment analysis.
- Otomatisasi Pencarian Informasi
Daripada mencari data secara manual, scraping website memungkinkan otomatisasi pengumpulan informasi seperti jadwal, harga, atau review produk.
- Efisiensi Waktu dan Tenaga
Dengan web scraping, pekerjaan yang biasanya membutuhkan waktu berjam-jam bisa diselesaikan hanya dalam hitungan menit.
Apakah Kita Boleh Melakukan Scraping ke Berbagai Situs?
Untuk pertanyaan tersebut jawabanannya adalah boleh, tetapi dengan syarat tertentu. Dalam praktik web scraping, ada beberapa aturan yang wajib diperhatikan agar aktivitas ini tetap legal dan etis:
- Periksa robots.txt
Setiap website biasanya memiliki file robots.txt yang berisi aturan tentang halaman mana saja yang boleh diakses crawler atau bot. Pastikan scraping hanya dilakukan pada bagian situs yang diizinkan.
- Patuhi Terms of Service (ToS)
Beberapa situs secara eksplisit melarang pengambilan data menggunakan bot. Membaca dan memahami ToS sangat penting agar aktivitas scraping tidak melanggar aturan hukum.
- Gunakan Data untuk Tujuan Edukasi atau Riset
Idealnya, scraping dilakukan untuk tujuan edukasi, penelitian, atau personal project. Menggunakan data hasil scraping untuk kepentingan komersial tanpa izin pemilik website bisa menimbulkan masalah hukum.
- Hindari Beban Server Berlebih
Jangan mengirim request terlalu cepat ke server target. Tambahkan delay agar scraping tidak dianggap sebagai serangan dan tidak mengganggu performa website.
Tools atau Library Yang Dibutuhkan
Untuk melakukan teknik scraping, kita akan menggunakan beberapa library Python seperti:
- Requests
- BeautifulSoup (bs4)
- SQLite3
Instalasi Library
Sebelum kita ngoding, kita perlu melakukan instalasi library yang kita butuhkan dengan perintah dibawah ini.
pip install requests beautifulsoup4
NOTE: Untuk library sqlite3 sudah bagian dari bawaan Python.
Implementasi
Buat file main.py pada root direktori project terlebih dahulu. Jika sudah, perhatikan langkah-langkah serta penjelasan dari proses implementasi dibawah ini.
- Import Library
import requests
from bs4 import BeautifulSoup
from urllib.parse import urljoin
import sqlite3
- Set Headers
HEADERS = {
"User-Agent": "Mozilla/5.0"
}
Dengan menambahkan headers, maka setiap request HTTP yang kita kirim akan terlihat seperti browser asli dan mengurangi resiko diblokir.
- Helper Untuk Mengambil URL Gambar
def extract_img_url(img, base_url):
for attr in ("data-src", "data-original", "data-lazy", "data-url"):
val = img.get(attr)
if val:
return urljoin(base_url, val)
srcset = img.get("srcset")
if srcset:
first = srcset.split(",").strip().split()
return urljoin(base_url, first)
src = img.get("src")
if src:
return urljoin(base_url, src)
return None
Banyak situs modern memakai atribut lazy-loading, sehingga URL gambar asli disimpan di atribut data-src, sedangkan atribut src hanya berisi placeholder. Fungsi dari helper ini memeriksa berurutan data-src → srcset → src sehingga menangkap URL gambar resolusi yang tepat. Pada srcset, pola “URL spasi descriptor (1x/2x/400w)” dipecah dan diambil URL pertama untuk hasil cepat dan stabil.
- Fallback og:image
def extract_og_image(article_url):
try:
r = requests.get(article_url, headers=HEADERS, timeout=15)
s = BeautifulSoup(r.text, "html.parser")
meta = s.find("meta", property="og:image") or s.find("meta", attrs={"name": "og:image"})
if meta and meta.get("content"):
return meta["content"]
except Exception:
return None
return None
Jika suatu halaman hanya memuat placeholder, metadata og:image pada halaman artikel hampir selalu menunjuk ke thumbnail utama. Fallback ini meningkatkan keberhasilan pengambilan gambar tanpa harus menebak struktur internal setiap widget gambar.
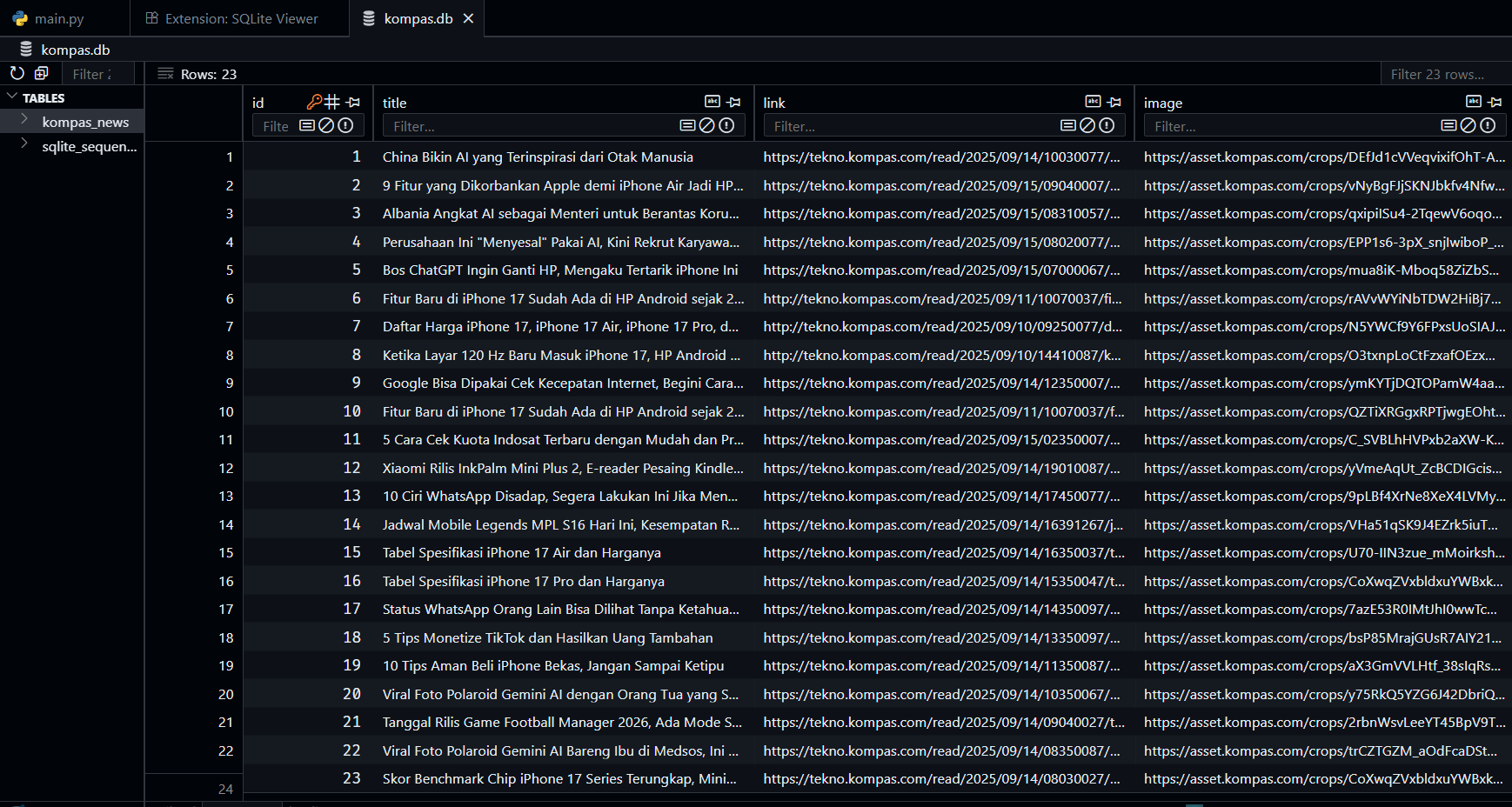
- Membuat Koneksi SQLite
conn = sqlite3.connect("kompas.db")
cursor = conn.cursor()
cursor.execute("""
CREATE TABLE IF NOT EXISTS kompas_news (
id INTEGER PRIMARY KEY AUTOINCREMENT,
title TEXT,
link TEXT UNIQUE,
image TEXT
)
""")
conn.commit()
- Scraping Data Artikel Dari Beranda
base = "https://tekno.kompas.com/"
resp = requests.get(base, headers=HEADERS, timeout=20)
soup = BeautifulSoup(resp.text, "html.parser")
articles = soup.find_all("div", class_="article__grid")
Pada proses web scraping, halaman target akan diunduh dan diparse, kemudian setiap kontainer artikel dicari melalui class article__grid sesuai struktur DOM. Bagian inilah yang berisi judul berita, tautan artikel, serta elemen gambar.
- Ekstraksi Data dan Menyimpan ke Database
for article in articles:
title_tag = article.find("h3", class_="article__title")
title = title_tag.get_text(strip=True) if title_tag else None
link_tag = title_tag.find("a") if title_tag else None
link = link_tag["href"] if link_tag and link_tag.has_attr("href") else None
img_tag = article.select_one("div.article__asset img") or article.find("img")
image = extract_img_url(img_tag, base) if img_tag else None
# Fallback: get og:image if no image found
if not image and link:
image = extract_og_image(link)
if title and link:
cursor.execute(
"INSERT OR IGNORE INTO kompas_news (title, link, image) VALUES (?, ?, ?)",
(title, link, image)
)
conn.commit()
print("Data has been saved to kompas.db")
Penjelasan dari kode diatas:
- Pada tahap web scraping, judul dan link berita diambil dari elemen
h3.article__title melaluidengan taga[href]di dalamnya - Untuk gambar thumbnail, scraper mencari elemen img di dalam
div.article__assetjika tidak ditemukan, maka digunakan fallback ke gambar pertama dalam article card. - Proses ekstraksi gambar juga disesuaikan agar kompatibel dengan teknik lazy-loading, sehingga atribut data-src, srcset, maupun src tetap terbaca.
- Data dimasukkan ke SQLite database dengan syntax
INSERT OR IGNORE, sehingga scraping berulang tidak membuat baris duplikat untuk link yang sama.
- Hasil Implementasi Buka terminal, dan ketikkan perintah dibawah ini.
python main.py
Jika berhasil, maka tampil pesan seperti ini pada terminal.
 Setelah itu cek root direktori project kalian masing-masing dan pastikan ada file baru bernama
Setelah itu cek root direktori project kalian masing-masing dan pastikan ada file baru bernama kompas.db seperti dibawah ini.
 Sebelum membuka file tersebut, install sebuah extension VS Code bernama SQLite Viewer agar kita bisa membaca file dari SQLite melalui VS Code.
Sebelum membuka file tersebut, install sebuah extension VS Code bernama SQLite Viewer agar kita bisa membaca file dari SQLite melalui VS Code.
Kesimpulan
Melakukan web scraping pada website kompas.com dengan Python bisa dilakukan dengan mudah menggunakan library requests dan BeautifulSoup. Hasil scraping dapat digunakan untuk analisis trend berita, text mining, hingga machine learning.
Terimakasih.
